

Is AMD Undervalued After The Latest GPU Release?
Comparing Nvidia vs AMD latest release of GPU. The ability for AMD to potentially carve out a sizeable portion of the AI data center market share.
Nvidia vs AMD: How the Latest GPU Releases Will Set the Stage for AI’s Next Decade
AMD aims to compete NOT by beating Nvidia everywhere, but by being GOOD ENOUGH where it matters most
Introduction: The GPU War That Will Define AI in 2026+
For the past several years, Nvidia has been synonymous with AI. If you trained a large language model, ran a hyperscale data center, or built an autonomous system, chances are it ran on Nvidia GPUs.
But 2026 marks a structural shift.
With Nvidia’s Rubin R200 and AMD’s Instinct MI400 series, we’re no longer just talking about faster chips. We’re talking about who controls the economics of AI compute as the industry moves from experimental training runs to always-on, real-world inference at planetary scale.
This article breaks down:
- Why AI compute demand is exploding toward Yottascale
- How Nvidia Rubin R200 compares to AMD Instinct MI400 in practical terms
- Why Nvidia has been nearly impossible to dethrone (CUDA vs ROCm)
- Why ROI, cost, and workload segmentation may finally open the door for AMD
And most importantly:
Why 2026 could be the year AMD stops being “the alternative” and starts being essential.
1. AI Compute Enters the Yottascale Era
From Zetta to Yotta: A 100× Shock to the System
When ChatGPT launched in 2022, global AI compute capacity was estimated at roughly 1 zettaflop.
Fast forward just a few years:
- Global AI compute capacity has surged nearly 100×
- We are approaching 100 zettaflops
- And we are now racing toward Yottascale
This is not linear growth. This is an infrastructure shock.
How Big Is Yottascale, Really?
To make this concrete:
- 1 Exaflop = 1018 Operations Per second
- 1 Zettaflop = 1,000 Exaflops = 1021 Operations per second
- 1 Yottaflop = 1,000,000 Exaflops = 1024 Operations per second
Why This Leap Is Happening: The Shift to Inference
Training large models made headlines.
Inference is what breaks the grid.
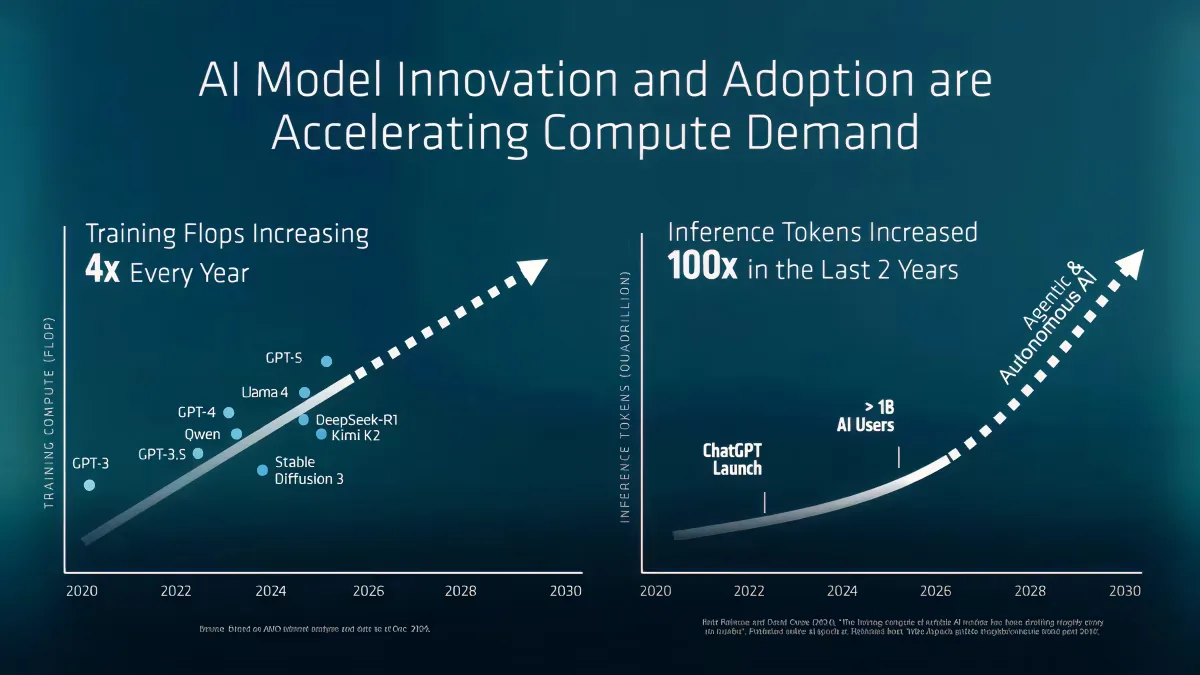
We’ve crossed a critical inflection point where AI demand is no longer driven by training alone, but by Inference at Scale:
- Autonomous agents running 24/7
- Multimodal systems processing text, images, video, 3D, and sensors
- Continuous reasoning, not single-prompt responses
- Embedded AI inside enterprise workflows, robotics, logistics, and finance
In simple terms:
AI is no longer something you ask.
It’s something that’s always working.
From Assistive to Transformational
Reaching Yottascale unlocks capabilities that were previously impossible:
- Healthcare: Real-time diagnostics, protein folding, and drug discovery
- Climate science: Ultra-high-resolution weather and physics simulations
- Physical AI: Autonomous factories, warehouses, and transport networks
- Hyper-personal agents: Always-on copilots managing your work and digital life
Zettascale got us smart assistants.
Yottascale gives us autonomous systems.
2. Nvidia Rubin R200 vs AMD Instinct MI400: What the Specs Actually Mean
Before diving into numbers, let’s translate GPU jargon into real-world impact.
What These Specs Mean (In Plain English)
- Manufacturing Node: Smaller nodes = more transistors = more performance per watt
- FP4 Inference: How efficiently the GPU runs everyday AI queries
- FP8 Training: How fast models can be trained or fine-tuned
- HBM Capacity: How much “working memory” the GPU has for large models
- Memory Bandwidth: How fast data moves between memory and compute
- Interconnect: How well GPUs talk to each other at rack scale
AI is rarely limited by raw compute alone.
Side-by-Side Comparison
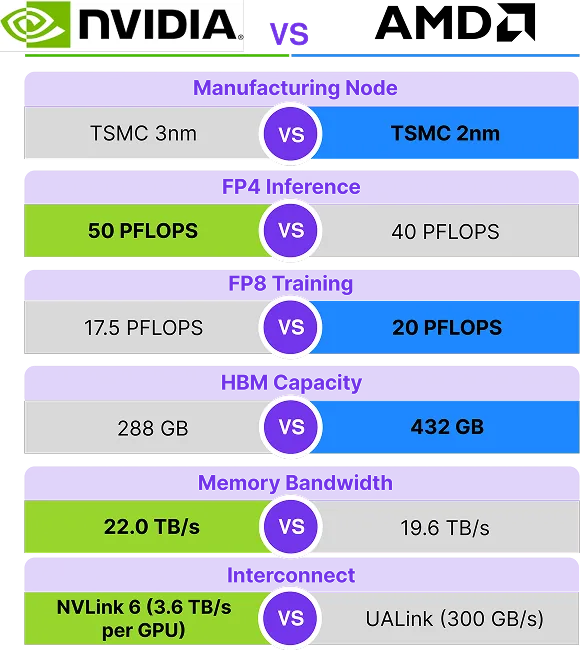
Manufacturing Node: Nvidia - TSMC 3nm vs AMD - TSMC 2nm
FP4 Inference: Nvidia - 50 PFLOPS vs AMD - 40 PFLOPS
FP8 Training: Nvidia - 17.5 PFLOPS vs AMD 20 PFLOPS
HBM Capacity: Nvidia - 288GB vs AMD - 432 GB
Memory Bandwidth: Nvidia - 22.0 TB/s vs AMD - 19.6 TB/s
Interconnect: Nvidia - NVLink 6 (3.6 TB/s per GPU) vs AMD - UALink (300GB/s)
The Key Takeaway
- Nvidia still wins peak performance and scaling maturity
- AMD is optimizing for cost-efficient inference at scale
This difference is not accidental.
It reflects where each company believes the market is going.
3. Why Nvidia Has Been Nearly Impossible to Dethrone
Nvidia's CUDA vs AMD's ROCm: The Real Moat
Nvidia’s dominance isn’t just about silicon.
It’s about CUDA(Compute Unified Device Architecture).
CUDA is not a programming language.
It’s an entire AI civilization built over 15+ years.
Foundational models, research pipelines, tooling, debuggers, libraries, and frameworks have all been optimized for Nvidia hardware.
Switching GPUs isn’t as simple as unracking old GPU and replacing with a new one.
It requires:
- Rebuilding software architecture
- Refactoring CUDA-optimized kernels
- Re-validating performance and accuracy
- Re-training engineering teams
- Accepting uncertainty in performance parity
Even if ROCm (Radeon Open Compute Platform) is technically capable, migration cost is massive.
This is why Nvidia could command premium pricing:
Customers weren’t just buying GPUs — they were buying for the whole build.
Why This Is Finally Changing
Three things are breaking this inertia:
-
Inference Workloads Are Less Sticky
Many inference tasks don’t require custom CUDA kernels. -
Cost Pressure Is Back
ROI is replacing “buy whatever Nvidia ships.” -
Hyperscalers Can Force Change
When OpenAI, sovereign funds, or hyperscalers commit, ecosystems follow.
This is where AMD enters the conversation — not by beating Nvidia everywhere, but by being good enough where it matters most.
4. The Market’s True Desire: ROI Over Brute Force
AI Will Segment by Complexity

The future AI stack will not be uniform. It will stratify.
A) High-Complexity Workloads (Nvidia-Dominant)
- Scientific simulations
- Advanced mathematical modeling
- Autonomous agentic systems
- Financial modeling and real-time trading
- Robotics and physical AI
These workloads demand:
- Peak performance
- Mature tooling
- Guaranteed scaling behavior
Nvidia remains king here.
B) Mid-to-Low Complexity Workloads (AMD’s Opportunity)
- Document summarization
- Search and retrieval
- Customer support AI
- Enterprise copilots
- Routine inference tasks
These workloads represent:
The majority of AI consumption.
They don’t need maximum performance.
They need cost-efficient, reliable throughput.
This is where AMD shines.
The Catalyst: AMD, OpenAI, and the 6–10 Gigawatt Bet
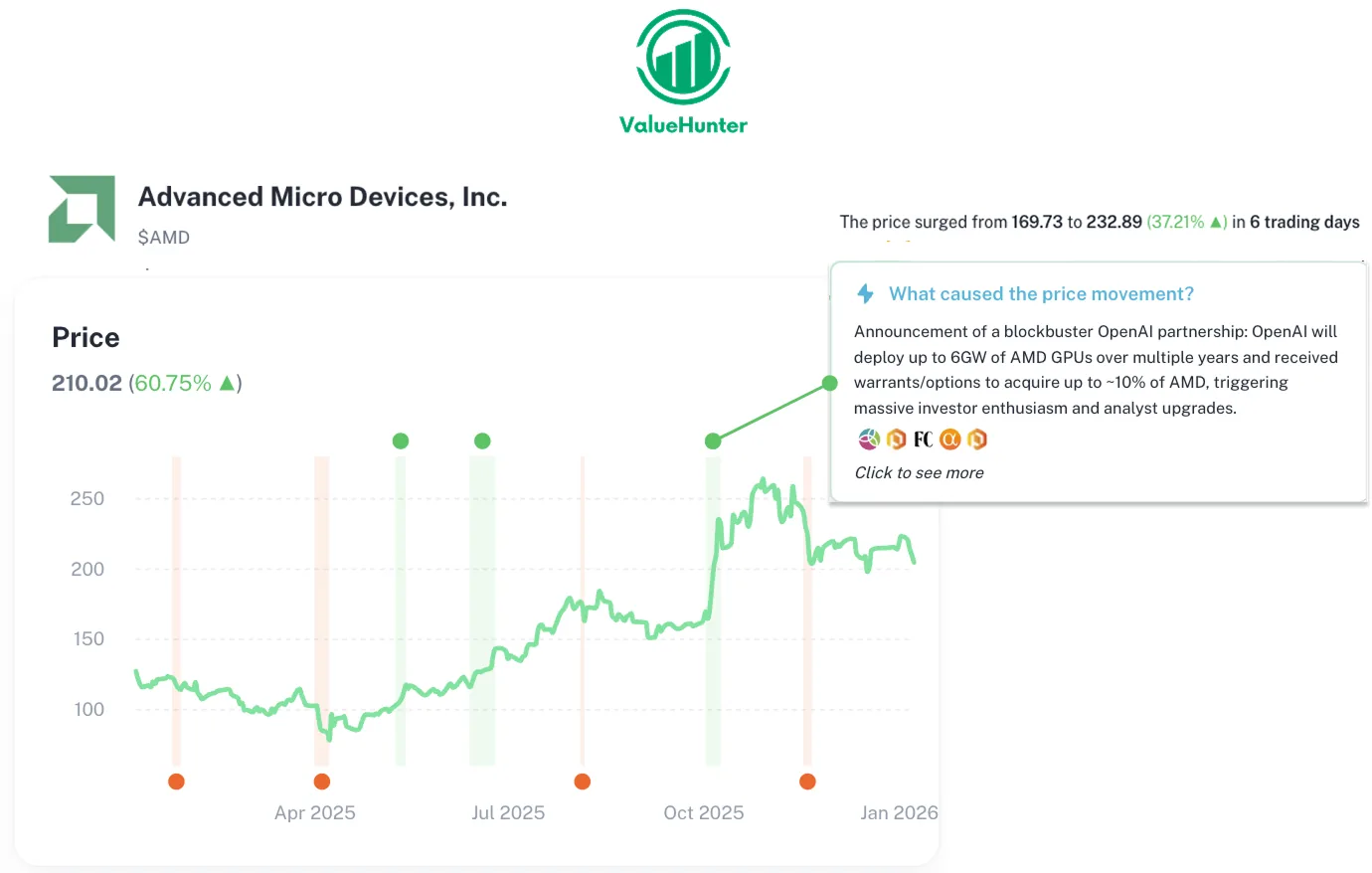
The OpenAI Deal That Changed Everything
- 6 gigawatts of AMD Instinct GPUs (MI450 / MI500 series)
- Built toward OpenAI’s Stargate project
- Total capacity potential: 10GW
- Implies AMD supplying ~60% of a major AI player’s compute
Even more striking:
- OpenAI is reportedly allowed to take up to ~10% equity stake in AMD
This isn’t a vendor relationship.
This is strategic partnership.
Now everything hinges on one thing:
How does the shift over to MI455X fare for OpenAI compared to what it has always been with Nvidia?
If it’s “close enough” and “easy enough,” the market changes overnight.
Cracks in the Monopoly
We’re already seeing it:
- Saudi sovereign AI deals split between Nvidia and AMD
- AMD winning smaller but strategic footholds
Deals AMD wouldn’t have even been invited to five years ago
Nvidia still wins the bigger checks.
But AMD is finally in the room.
Market Share Reality Check
- Nvidia: 90–95% of AI data center GPUs
- AMD: ~4% today
But measured in gigawatts of deployed compute, AMD is moving into double-digit share.
That’s not symbolic.
That’s structural.
The Valuation Question No One Wants to Ask (But Should)
Nvidia market cap: ~$4.6 trillion
Market share: ~90–95%
If AMD captures:
- 10% AI compute share → $460B implied value
- That’s roughly 35% upside from current levels
- Now imagine if AMD takes 15% or 20% of the market share
And remember:
Most AI workloads are not high-complexity.
As AI architectures mature, ROI-driven compute allocation becomes inevitable.
That future favors AMD.
Conclusion: 2026 Is AMD’s Moment
Nvidia will remain the performance leader.
That’s not in dispute.
But the AI market is no longer about who is fastest.
It’s about who is economically scalable.
AMD doesn’t need to dethrone Nvidia.
It needs to become indispensable.
With:
- Lower cost solution for majority consumer AI usage
- Strategic OpenAI alignment
- Growing sovereign and hyperscale wins
- A market shifting from brute force to ROI
AMD is no longer just the underdog.
It’s the pressure valve for an AI industry racing toward Yottascale.
Next Steps
Disclaimer: The information provided is for educational purposes only and should not be considered financial or investment advice. Always do your own research
For latest news and deeper dive into AMD (click here)
For latest news and depper dive into NVDA (click here)
Log in to start your own research and stay informed
Sources:
https://www.amd.com/en/corporate/events/ces.html
https://www.amd.com/en/newsroom/press-releases/2026-1-5-amd-and-its-partners-share-their-vision-for-ai-ev.html
https://www.amd.com/en/blogs/2026/from-ces-2026-to-yottaflops-why-the-amd-keynote.html
https://www.amd.com/en/newsroom/press-releases/2026-1-5-amd-expands-ai-leadership-across-client-graphics-.html
https://blogs.nvidia.com/blog/2026-ces-special-presentation/
https://nvidianews.nvidia.com/news/rubin-platform-ai-supercomputer
https://www.nvidia.com/en-us/events/ces/